APO使用场景之:统一的指标采集展示

可观测性领域中的指标一直都占有非常重要的地位。Prometheus生态目前已经是事实上的标准,但是实际用户在落地Prometheus的时候可能存在以下的问题:
- 虽然生态中有各种成熟的Exporter,但是各种Exporter的安装配置相对而言比较繁琐,管理比较麻烦
- 跨集群的指标数据汇聚相对而言比较麻烦,很多时候需要二次开发,没有简单配置即可工作的工具
- Prometheus 原生数据存储在大数据量时不稳定,业界有着很好的类似VictorioMetrics方案,但是很多人还未尝试使用
- 业界也存在过万好评的大屏,��能够更好体现指标价值,对于很多用户而言可能并不了解
在APO中能够很好的解决以上的问题,已经将指标生态的各种产品进行很好的整合。
Grafana Alloy介绍
Alloy是Grafana 发布替代之前Grafana Agent的开源产品。
简单的官方介绍:
“Grafana Alloy 是一个开源的 OpenTelemetry Collector 发行版,内置 Prometheus 管道,并支持度量、日志、追踪和性能剖析。”
更为详细的官方介绍:
“Alloy 为 OTel、Prometheus、Pyroscope、Loki 以及许多其他指标、日志、追踪和分析工具提供了原生管道。此外,您可以使用 Alloy 管道执行各种任务,例如在 Loki 和 Mimir 中配置警报规则。Alloy 完全兼容 OTel Collector、Prometheus Agent 和 Promtail。您可以将 Alloy 作为这些解决方案的替代方案,或将其与多个收集器和代理结合成混合系统。您可以在 IT 基础设施的任何地方部署 Alloy,并将其与 Grafana LGTM 堆栈、Grafana Cloud 的遥测后端或任何其他供应商的兼容后端配对。Alloy 灵活多变,您可以轻松配置以满足本地部署、仅云部署或两者结合的需求。”
APO是如何使用Grafana Alloy
从Grafana Alloy的官方介绍中可以看出Alloy很强大,但APO并未使用Alloy所有的功能,主要使用以下两个功能:
- 集成管理各种Prometheus的exporter的功能,有兴趣的朋友可以翻之前文章介绍了如何使用Alloy一键配置完成exporter的指标采集
- 管道功能:跨云,跨集群,跨网段的指标采集之后要传输到统一可观测性后台展示
集成管理Prometheus各种exporter功能
通过简单配置即可完成exporter的配置、安装部署:比如通过以下的配置,即可实现ElasticSearch 的exporter的部署和采集
# 采集 elasticsearch指标
prometheus.exporter.elasticsearch "example" {
address = "http://<elasticsearch-url>:9200"
basic_auth {
username = USERNAME
password = PASSWORD
}
}
prometheus.scrape "mysql" {
targets = prometheus.exporter.elasticsearch.example.targets
forward_to = [otelcol.receiver.prometheus.default.receiver]
}
数据的管道功能
管道功能,数据可以通过OpenTelemetry的collector完成数据的跨集群、跨网络、跨云的传输。
数据流向:
Alloy(采集指标)-> Otel Collector (网络边界)->(网络边界) Otel Collector -> VictoriaMetric
管道功能核心的逻辑在于通过简单配置OTEL collector
- recievier
- exporter
配置示例:
边缘侧 Collector 配置(负责接收指标并发送到中心 Collector):
边缘侧 Collector 将通过 OTLP 接收指标数据,并通过 OTLP 发送到中心侧 Collector。
配置示例(边缘侧 Collector):
receivers:
otlp:
protocols:
grpc: # 支持 gRPC 和 HTTP 协议
http:
exporters:
otlp:
endpoint: "http://center-collector:4317" # 中心 Collector 的接收地址
metrics:
resource_to_telemetry_conversion:
enabled: true # 将资源级信息转换为 Telemetry 数据
service:
pipelines:
metrics:
receivers: [otlp] # 从应用接收 OTLP 格式的指标数据
exporters: [otlp] # 导出到中心 Collector
中心侧 Collector 配置(负责从边缘侧 Collector 接收指标并写入存储系统):
中心侧 Collector 将通过 OTLP 接收边缘侧 Collector 发来的指标数据,并将其导出到最终的存储后端。
配置示例(中心侧 Collector):
yaml
Copy code
receivers:
otlp:
protocols:
grpc:
http:
exporters:
prometheus:
endpoint: "http://prometheus:9090/metrics" # Prometheus 的接收地址
namespace: "otel_metrics"
service:
pipelines:
metrics:
receivers: [otlp] # 从边缘侧 Collector 接收 OTLP 格式的指标数据
exporters: [prometheus] # 导出到 Prometheus
配置说明:
1.边缘侧 Collector:
- receivers: 使用 otlp 接收应用程序发送的指标数据,支持 gRPC 和 HTTP 协议。
- exporters: 使用 otlp 导出数据,endpoint 是中心侧 Collector 的接收地址。
2.中心侧 Collector:
- receivers: 使用 otlp 从边缘侧 Collector 接收指标数据。
- xporters: 使用 prometheus 将数据导出到VictorioMetrics。
APO如何看待Alloy其它功能
- Alloy集成Loki而来的日志能力,在实际使用日志场景中可能不够用,实际日志都要完成非结构化转化成结构化这一步骤,但是Loki在此方向并不擅长
- Pyroscope等Continues Profiling的数据目前在OpenTelemetry生态并未完全成熟,即便能够使用Alloy完成数据的采集,但是如何传输,存储,展示都成为问题,还有很多问题等着解决
Alloy的exporter集成能力是经过grafana agent项目能力沉淀而来,坑相对而言比较少。APO在实际使用Alloy也踩了些坑,通过不断调整配置,相信未来也会越来越稳定。
VictorioMetrics的使用
VM已经成为很多公司存储指标的首选,主要是相比prometheus其它生态产品而言
架构简洁性:
-
VictoriaMetrics: VictoriaMetrics 集群版的架构较为简单,支持单一二进制文件启动,减少了复杂的集群管理工作。它既可以用作单机部署,也可以扩展为分布式集群,支持水平扩展,且维护相对简单。
-
Thanos/Cortex: 这两者的架构相对复杂,通常需要多个组件(如 Querier、Store Gateway、Compactor 等)协同工作,且往往涉及到对象存储(如 S3、GCS 等)来进行长期存储。因此,它们的配置、部署和维护难度较高,适合需要长时间数据保留的大规模��集群。
高效存储和压缩:
-
VictoriaMetrics: 其高效的数据压缩和存储引擎使其在处理大量数据时更加节省存储空间。它采用自定义的存储格式和时间序列压缩算法,特别擅长处理大规模高频率的时间序列数据。
-
Thanos/Cortex: 这两者依赖于 Prometheus 的存储块和外部对象存储来处理长时间的数据保留,并通过外部系统进行压缩。虽然通过对象存储解决了长期存储问题,但这种方式带来的延迟和复杂性较高,尤其是在查询大量历史数据时,可能会受到网络和存储系统性能的影响。
性能和查询速度:
-
VictoriaMetrics: 由于其优化的存储引擎和索引机制,VictoriaMetrics 在长时间范围的查询场景中通常表现更好。它可以处理大规模数据的高性能写入和快速查询,即使在单节点场景下也能保持良好的表现。
-
Thanos/Cortex: 这两者的查询性能取决于集群的规模和外部存储的读写性能,尤其在跨多个 Prometheus 实例进行查询时,由于依赖对象存储,查询速度相对较慢。此外,Cortex 使用分区和多租户设计,虽然增强了灵活性,但在某些场景下也会引入查询延迟。
完全兼容 Prometheus API:
VictoriaMetrics 完全兼容 Prometheus 的查询语言(PromQL)和数据采集接口,能够无缝替代 Prometheus,且支持从 Prometheus、Thanos、InfluxDB 等系统中直接导入数据,迁移成本低。
指标的统一展示
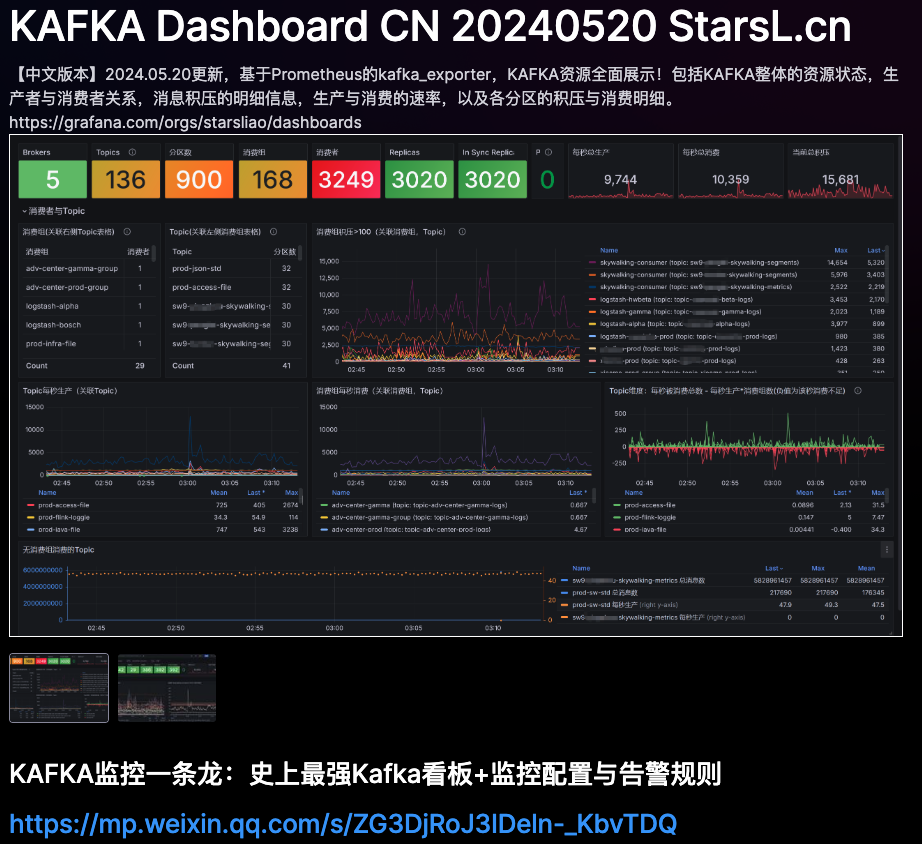
当各种prometheus exporter的数据存储在VictorioMetrics之中,可以利用生态已有的Grafana大屏直接展示,感谢StarsLiao的贡献,在其贡献的大屏中,有很多已经成为众多公司的选择,很多大屏有着上万的好评。APO中很多大屏都引入了大佬的作品。
总结
APO利用Prometheus和OpenTelemetry的成熟生态成果,快速完成指标的采集、传输和统一展示。虽然这些能力并不是APO的核心价值,但也是可观测性平台的核心支柱能力,也欢迎用户先将APO当成指标的采集、传输和统一展示的工具,当系统越来越复杂,需要集成Trace、日志等能力之时,用户可以不用迁移平台。
APO介绍:
国内开源首个 OpenTelemetry 结合 eBPF 的向导式可观测性产品
apo.kindlingx.com